How we built this
The problem we’re trying to solve is that code example diffs can be noisy. An example of noise would be changes related to refactoring code from previous stages.
Here’s an example of a noisy diff from the “exit builtin” stage where a user is supposed to add support for the exit to their shell:

This example does far more than add support for exit. It also adds REPL functionality with the while True loop. The changed lines also include the code to print a prompt, read input etc – all of which correspond to functionality from other stages.
We took an early stab at solving this problem with "Concise" code examples. The concise example for the stage above looked like this:

This only identified one example though, so the rest of the list was still noisy.
This time we wanted to find a solution that would make every code example diff less noisy, not just a select few.
We know that every code example passes our tests. So every code example must have relevant code in it, we just don’t know where it is. Instead of relying on a user’s diff, we could use LLMs to highlight the relevant lines of code for a code example.
Pass in stage instructions, the user’s code and then ask the LLM to make a tool call to highlight relevant lines of code.
“Prompt Engineering”
It took us 10 minutes to make the first version of the prompt that does highlighting. Making this reliable, handling edge cases and optimizing costs took almost a week!
We started with 10 manually annotated code examples and a hacky eval script:

The initial tweaks were pretty obvious - for example, the LLM would often get line numbers wrong, so we had to include line numbers in the prompt:

After we got the 10 examples passing, we then ran this against 100s of examples and manually scoured through them for failures and edge cases. None looked obviously wrong, but a common theme seemed to be that the LLM would often highlight a bit too much.
The error was obvious once we inspected a few samples. Although we asked the LLM to only highlight changes relevant to this stage, the LLM didn’t actually know which the previous stages were. This was context we hadn’t added in our prompt. This was the diff that added that in:
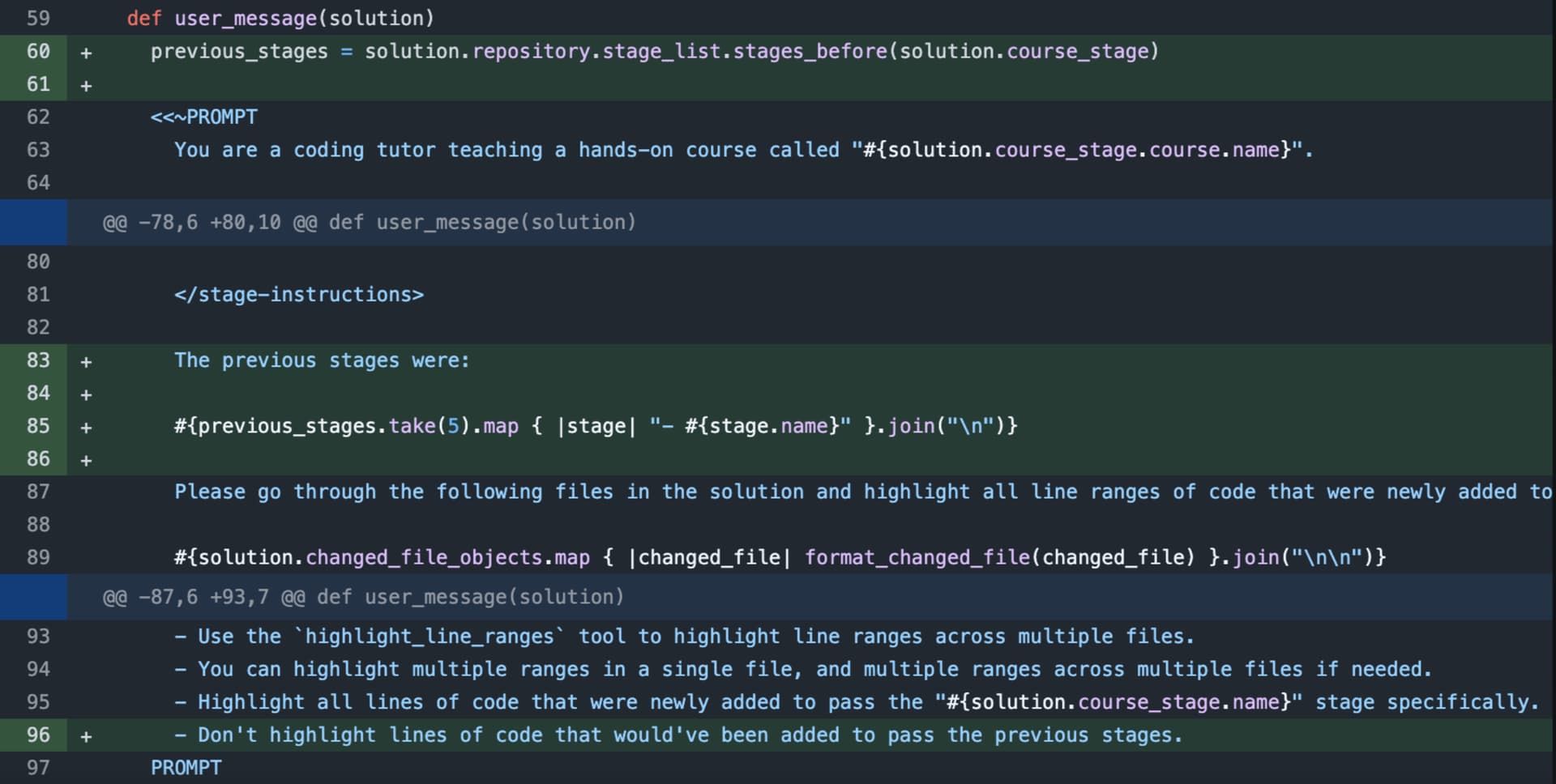
A few tweaks like this and we got to a point where our evals were consistently passing.
$$$ Engineering
Next, the fun part - optimizing costs. During development we used o3 since that anecdotally seemed to perform best. o3 wasn’t prohibitively expensive but it wasn’t exactly cheap either. It’d cost us $100-$200 a day and a one-time cost of $40k to highlight all code examples using o3.
Since we had evals, evaluating other models was a breeze. We started at o3 and start working our way down until we found the cheapest one that worked reliably. o4-mini seemed to perform just as well at 1/10th the cost, anything below that and we’d start seeing random eval failures. Using o4-mini brought our one-time costs down from $40k to $4k, a 90% reduction.
That’s about it! The rest was just the usual – minor UI tweaks, releasing to staff to test, running a batch job to highlight old examples etc.